I helped teach the Data Science and Data Engineering Bootcamp by Data Science Dojo in Singapore earlier this month. I came away with a refreshed appreciation of the importance of randomness which pops up frequently in techniques, and also a renewed love for ensemble methods. One of the things that students consistently found difficult was getting their head around the different evaluation metrics so here’s my attempt to explain and simplify.
One of the things which always surprises students is being able to write a machine learning algorithm in one line of code. How could it be so easy, they ask? And then we start to ask: is this model any good? What do the metrics tell you? And then students fall from the cliff of confusion very much into the desert of despair.
Binary Classification Metrics
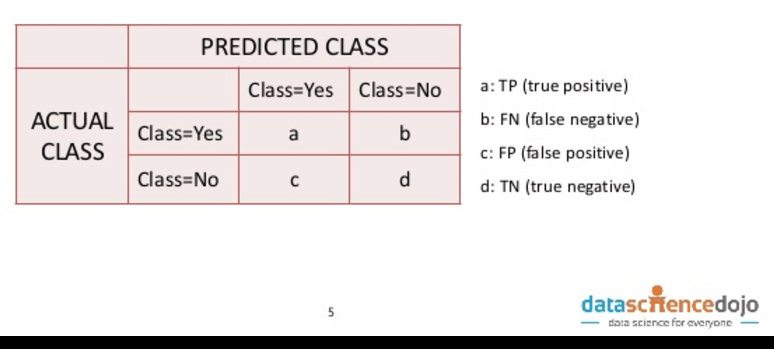
So a binary classification model predicts “yes” or “no” for an observation, for example, “is this a fraudulent transaction?” or “does this person have a disease?” There are 4 states of the world:
- You guess “yes” and it’s a “yes” – yay!
- You guess “no” and it’s a “no” – yay!
- You guess “yes” and it’s a “no” – less yay…
- You guess “no” and it’s a “yes” – less yay again…
These states are often put into a table called a “confusion matrix” (one hopes this is named ironically..!) and are said to be “true” if the actual class matches the predicted class, and “false” if it doesn’t.
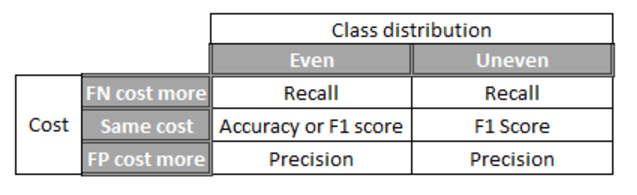
The simplest metric is accuracy: out of your predictions, how many are correct (true positive + true negative / total)? But accuracy turns out to not be a good measure for rare events. Sticking with the example of fraud: say 1 in every 1000 transactions is fraudulent, and you predicted that they all were fraudulent as a simple starting model, the accuracy of the model would be 99.9%. Not bad, right? But actually not helpful in giving you any action to take. As data scientists, we need to be aware of multiple metrics because data sets differ in two key ways:
- The ratio between positives and negatives (“the class distribution”) => this is rarely 50:50;
- The cost of wrong observations.
Accuracy is only good for symmetric data sets where the class distribution is 50:50 and the cost of false positives and false negatives are roughly the same. For example, if you were trying to predict whether someone is female (ignoring non-binary people for the sake of the example!) where there are roughly equal numbers of males and females, and the cost of a false positive (when you mark someone as female but they are actually male) and a false negative (when you mark someone as male but they are actually female) are about the same.
Precision looks at the ratio of correct positive observations to all positive observations (true positives / (true positives + false positives). You improve precision by reducing the number of false positives. It is a measure of how good predictions are with regard to false positives and so is useful when false positives are costly. For example, whilst it may seem useful to detect as many cases of a disease as possible, if the cost of the treatment had serious side effects, you may want to reduce the number of false positives that you subject to the treatment unnecessarily.
Recall / sensitivity is the ratio of correctly predicted positive events (true positives / (true positives + false negatives)). It is a measure of how good predictions are with regard to false negatives and you improve it by reducing the number of false negatives i.e. missing true cases. You will want to focus on improving recall / sensitivity when the cost of missing a case is big, for example, in predicting terrorism.
The F1 score is the harmonic mean of precision and recall – this is for cases where an uneven class distribution matters and if false positives and false negatives have similar costs. For example, in the case of tax dodgers (few relative to population i.e. an uneven class distribution), it may be equally costly to miss a tax dodger (due to the lost tax revenue) and to accuse someone of dodging tax (due to the undermined trust). You take the harmonic mean instead of a simple mean because the denominators for calculating precision and recall are different, and so it doesn’t make sense to calculate a simple mean*.
You can also have other combinations of precision and recall which reflect how much you care about each. This is known as the F-beta where beta is how much more you care about recall. This is then useful in translating actual costs of false positives and negatives into the metric. For example, say the cost of falsely identifying an employee as leaving their role costs the company $1,000 in a pay rise, and the cost of missing that an employee is leaving costs the company $10,000. in replacing them, then you’d use an F10 score as the cost of the false negative is 10x the cost of the false positive.
The important thing to remember in all of this is that whichever type of error is more important or costs more is the one that should receive more attention.
In cross-validation, you’re running the algorithm on multiple samples of the data and so it creates lots of values for the metrics. Look at the mean and standard deviation of the metrics. Ideally, you want a high mean (accuracy, precision, recall / sensitivity, F1 score) and low standard deviation which suggest low bias and low variance respectively BUT there is a trade-off between bias and variance which means that you’re always looking for the sweet spot between low bias (illustrated by the high mean) and low variance. As you increase the model complexity you decrease the bias but if you go too far you end up overfitting and increasing the variance. If there is a low standard deviation but also low mean you can increase the complexity of your model. If there is a high mean but high standard deviation also it probably means that you’ve overfitted your model.
Practically speaking, you can decrease the complexity by doing things like reducing depth, increasing the minimum number of samples per leaf node or decreasing the number of random splits per node in tree-based models. Do the opposite to make your model more complex. I would highly recommend trying to change one parameter at a time and observing the change to the mean of which metric you’re using and the standard deviation.
The table below summarises how to choose the evaluation metric:
Continuous Variable Model Metrics
When predicting a continuous variable, the idea of being right or wrong for each prediction doesn’t really work. As an example, if I have the task of predicting the height of a group of people, I am not predicting “are they exactly 170cm tall?” The answer for pretty much everyone would be “no”. So I have to predict a height for each person depending on their characteristics. This is a rather sad way to put it but predicting a continuous variable is about minimising how wrong you are. For this reason, the above framework of true positives and true negatives doesn’t really work. So we need to turn to some other metrics to evaluate how good our continuous model is.
RMSE is the root mean squared error. It is calculated by taking the difference between the square of predicted variable, say house price, and the square of the actual house price, and then taking the square root. It gives you an idea of how far the predicted values are from the actual values. The fact that it involves squaring the predicted house price and the actual house price means that the RMSE overweights large errors in prediction. This is important when predicting well on outliers is particularly important.
If predicting on outliers is not important (e.g. if they probably represent measurement error in your equipment) then you can use MAE (mean absolute error) which is just the average of the difference between the predicted value and the actual value.
In practice, the RMSE and MAE are used less commonly than R squared (also known as the “coefficient of determination”) as R squared is standardised. R squared is effectively the ratio between explained variation and total variation observed. The values of R squared are only between 0 and 1 with 0 being the worst model (no variation explained) and 1 being the best (all observed variation explained by the model). (Well, actually the R squared can go below 0 but this would mean that your model would explain less than simply guessing the mean which is terrible!) The fact that R squared is standardised means that it’s a lot easier to develop an intuition around whether it indicates a good or a bad model compared with RMSE and MAE. One thing to note is that the R squared always increases when you more variables to your model. The adjusted R squared adds a penalty for every variable you add so that you don’t overfit. The disadvantage of the adjusted R squared is that it weights each parameter added equally and so doesn’t take into account that adding x3 may be worthwhile because it explains lots of the variance but adding x6 isn’t worthwhile because it’s not adding that much.
*See the second answer on this stack overflow.